AR グラス Nreal Light のアプリを開発するための NRSDK(Nreal SDK) for Unity のバージョン 1.4.8 がこの9月に出た。1.3.0 の次が 1.4.8 なのがちょっと謎。
Release Note のうち、機能追加にあたるのは以下の通り。
- Added running state tips (temperature, battery, lost tracking notifications)
- Added dynamic switch of 6DoF/3DoF/0DoF
- Supported Nreal Dimmer
- Added "IsTouching" API in NRInput
- Adapted to smartphone screen resolution change when NRSDK is running
- Adapted to Unity 2019.4 LTS
Unity 2019.4 LTS への対応を明示してくれるようになったのが地味に嬉しい。
Unity の特定のバージョン以外で NRSDK を使うと、アプリを起動してしばらくしたらメモリリークして落ちたりするので、Unity ガチャで NRSDK がちゃんと使えるバージョンを引くまで結構面倒だった。
2019.4 LTS と NRSDK 1.4.8 の組み合わせでは今のところかなり安定して使えている。
それ以外も地味な機能ばかり……。
Nreal のサイトに、まるですでに対応しているかのように書かれているハンドトラッキングは、いったいいつになったらサポートされるんだ。
AR グラスのインターフェースの本命はやっぱりハンドトラッキングだと思うので、今の画像タグや平面認識と同レベルでもいいから早いところ公開してほしい。
気を取り直して。
地味とはいえ、せっかくの新機能なので使い方をチェックしておきたいところ。
しかし Nreal のドキュメントは1日で読んで試し終わるくらいの分量で、新機能についての記述はなく。API Reference はカラッポ。
せめて NRSDK の github があればよかったのだが、いつまでたっても Coming Soon。
というわけで 1.3.0 と 1.4.8 の diff 見比べて、ソースを読み、新機能の使い方を洗い出してみた。
Nreal Dimmer はなんのことかわからず、IsTouching in NRInput はさすがに想像がつく(そして想像通り)。smartphone screen resolution change は純正 computing unit には多分関係ない?*1
そこで残りの running state tips と dynamic switch of 6DoF/3DoF/0DoF についてまとめる。
running state tips (temperature, battery, lost tracking notifications)
バッテリーの残量やグラスの温度について2段階の警告(Middle/High Level)を表示できる。トラッキング(SLAM State)は失っているかどうかだけで段階はない。
これを使うには、まず UI Canvas をシーンに追加して、そこに UI 部品の Text を2個(title, message), Image, Button を適当に配置する。Button は無くてもいいが、追加する場合は Nreal のドキュメント Controller の Building a Project with User Input にしたがって Canvas の構成をいじる。
この Canvas に "NR Notification Window" というコンポーネントを追加し、Icon/Title/Message/Confirm Btn にさきほどの Image, Text×2, Button をひもづける。*2
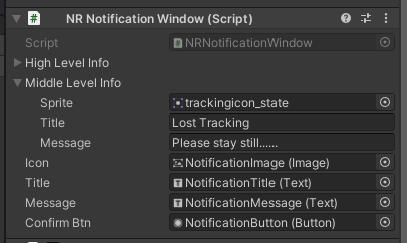
NR Notification Window の Middle Level Info と High Level Info を開いて、Sprite/Title/Message に適当なアイコン画像やテキストを設定する。アイコン画像は NRSDK にそれっぽいのが含まれているので、そのまま使ってもいい。

High と Middle の違いは、ソースやアイコン画像名(苦笑)を信じれば以下の通り。tracking では Middle Level Info しかつかわない。
| Middle | High | |
|---|---|---|
| 電池残量 | 40% 以下 | 30%以下 |
| グラスの温度 | 45度以上 | 55度以上 |
| トラッキング | Lost | --- |
次に空のゲームオブジェクトをシーンに追加して(紛れなければ既存のオブジェクトでもOK)、Component に "NR Notification Listener" を追加する。
Low Power と SLAM State と High Temp のうち、使いたいものを選んで Enable にチェック、Notification Prefab に先ほどの NR Notification Window を追加したオブジェクト(今の場合は Canvas)を設定する。
ここで注意しないといけないのは、使わない通知項目も含めて3か所ともすべてに NR Notification Window を設定しないといけないこと。これを怠ると、NRNotificationListener.Awake() が NullReferenceException を吐いて通知機能が働かない(Nreal ぇ……)。

これで完成。上述の条件を満たすと UI Canvas が表示され、各レベルに設定したアイコンやテキストが表示される。ボタンは High Level 時のみ表示され、これをクリックするとアプリケーションが終了する。
電池や温度は確認に時間かかるが、トラッキングはグラス前面のカメラをふさぐだけでロストしてくれるので、動作確認が楽。

dynamic switch of 6DoF/3DoF/0DoF
サンプルの NRCameraRig をインスペクタで開いて、 "NRHMD Pose Tracker" コンポーネントの項目 "Tracking Type" から "Tracking 6/3/0 Dof" を選ぶことで、もともと静的にトラッキングモードを変更することはできていた。
バージョン 1.4.8 では この NRHMDPoseTracker に ChangeTo6Dof() などが生えて、これをアプリ実行中に叩くことでトラッキングモードを動的に変更できるようになった。使い道は……思いつかない(笑)。
この機能を使う最小サンプル。
以下のコンポーネントを作って、NRCameraRig に追加。
public class ChangeTrackingMode : MonoBehaviour { private NRHMDPoseTracker tracker; void Start() { tracker = GetComponent<NRHMDPoseTracker>(); } public void OnChangeTo3Dof() { tracker.ChangeTo3Dof(); } public void OnChangeTo6Dof() { tracker.ChangeTo6Dof(); } }
あとは UI Canvas に Change 6 DoF などのボタンを配置し、上で作った OnChangeTo6Dof() などに紐づければ OK。
3DoF にしたときの position は (0,0,0) になるみたいで、6DoF の状態で移動した後切り替えても初期位置に戻される。
























