VRC-LT という VRChat 上で LT 大会を行うイベントに、のこのこ参加させてもらって、CLIP で画像検索の簡単なサービスを書いてみた話をしてきました。
主催の @haru2036 さん、発表者&参加者の皆さん、ありがとうございました&お疲れ様でした~。
このブログ、VR や AR の記事がちらほらありますが、VRChat はなんか怖そうと手を出してませんでした。*1
@haru2036 さんは実はすごーく昔にサイボウズ・ラボユースでメンターさせてもらったことがあって、その縁で VRC-LT に誘ってもらい、ようやく VRChat を始める踏ん切りが付きました(笑)。
発表資料はこちら。
www.slideshare.net
ただ、しゃべり有り前提の資料なので、VRC-LT の録画を見るほうがいいかもしれません(↓のリンク先の1時間23分ごろから)。
vrc-lt #15 お疲れ様でしたー!
— kisugi@おじ会Vtuber (@kisugi_yazuma) 2022年11月26日
引き続き限定公開で、アーカイブの視聴が可能ですので、見逃した方やもう一回見たい方はどうぞです~ヽ(=´▽`=)ノ🌟 https://t.co/wHhy5gvMUp
さて、CLIP を一言で説明すると、画像とテキストを同じ潜在空間(512次元)に埋め込むモデルです。
画像とテキストが似ていたら、CLIP によって似ているベクトルにエンコードされることが期待できます。
ググラビリティの低さから OpenAI CLIP と呼ばれることも多いですね。
CLIP の応用範囲は広く、最近話題の Stable Diffusion をはじめとしたテキストから画像を生成するモデルの多くにも CLIP が組み込まれていますし、画像にキャプションを付けるモデルにも CLIP が使われているものがあります。
中でも最もシンプルな CLIP の応用が、「似ている画像とテキストが似ているベクトルにエンコードされる」という特徴をそのまま使った画像検索になります。
あらかじめ画像を全部長さ1のベクトルにしておくことで、入力されたクエリーテキストをベクトルにエンコードし長さ1に正規化、画像ベクトルと内積をとると、長さ1同士なのでコサイン類似度になります。
あとは topk をとるだけで画像検索の完成です。
CLIP の学習は、大量の GPU と大量の画像・テキストペアが必要なので自分でやるのは正直しんどいですが、いろんな会社や研究所が学習済みモデルを公開しています。
特に AI bot 「りんな」で有名な rinna さんが日本語 CLIP モデルを商用利用可能なライセンスで公開してくれているので、ありがたく使わせてもらうことにしましょう。*2
CLIP による画像検索の実力を見てみましょう。実装についてはあとで紹介します。
「バス」で検索すると、バスが大きく写った画像がヒットします。
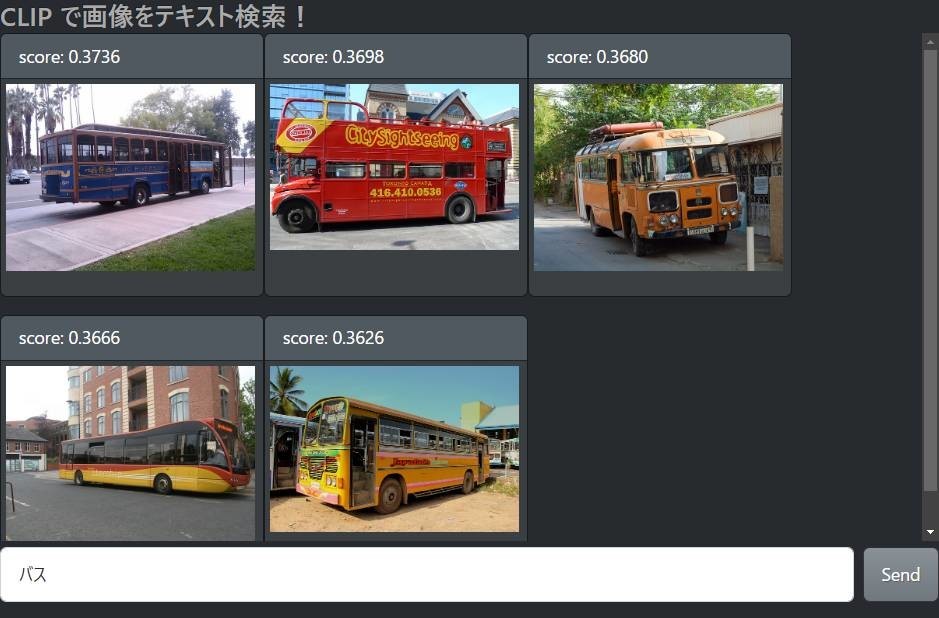
これくらいなら Google Photos の画像検索でもできそうですが、実際やってみると「確かにバスも写ってはいるけど……」みたいな写真がヒットすることも多いです。

Google Photos のような物体検出による画像検索は、基本的にその物体が画像に入っているかいないかだけを情報として取得して、それをもとにしたインデックスを検索しているので、こうした問題が生じます。つまり「バスの写真」ではなく「バスが写っている写真」を検索しているわけですね。
他にも、物体検出があらかじめ想定しているキーワード以外や、「青いバス」「寝ている猫」では検索できません。
さて、CLIP を使った潜在ベクトル検索はどうでしょう。
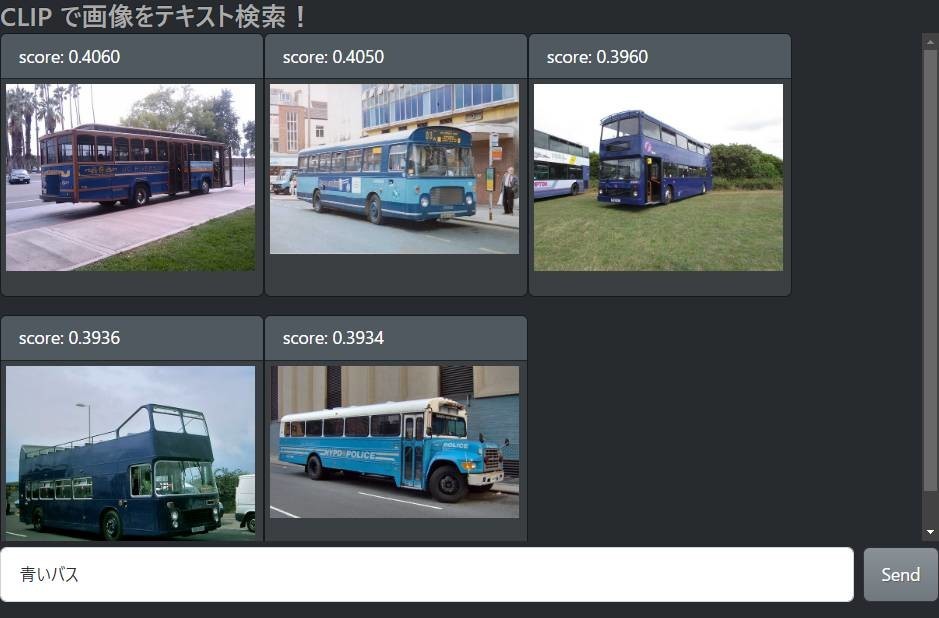
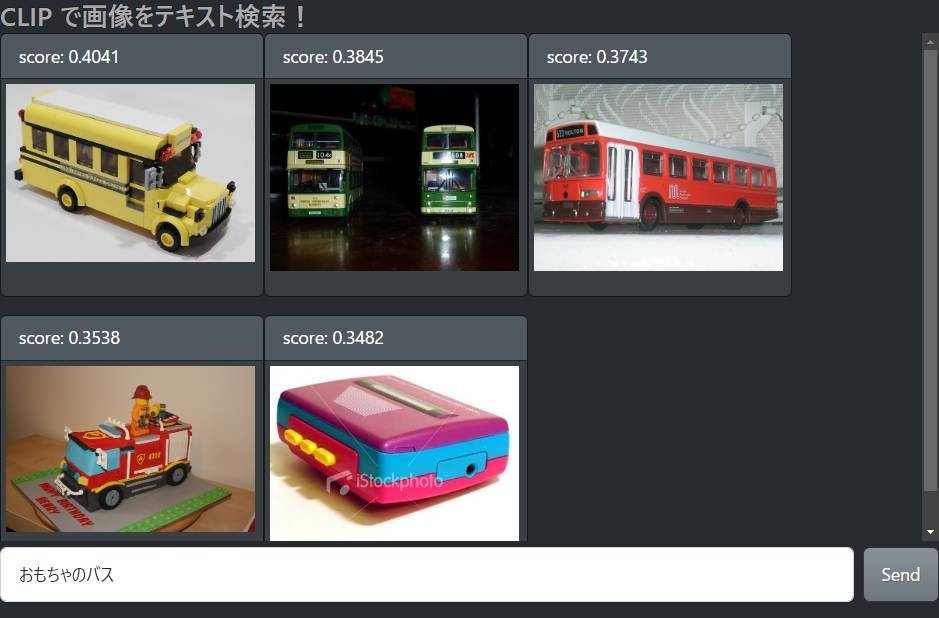
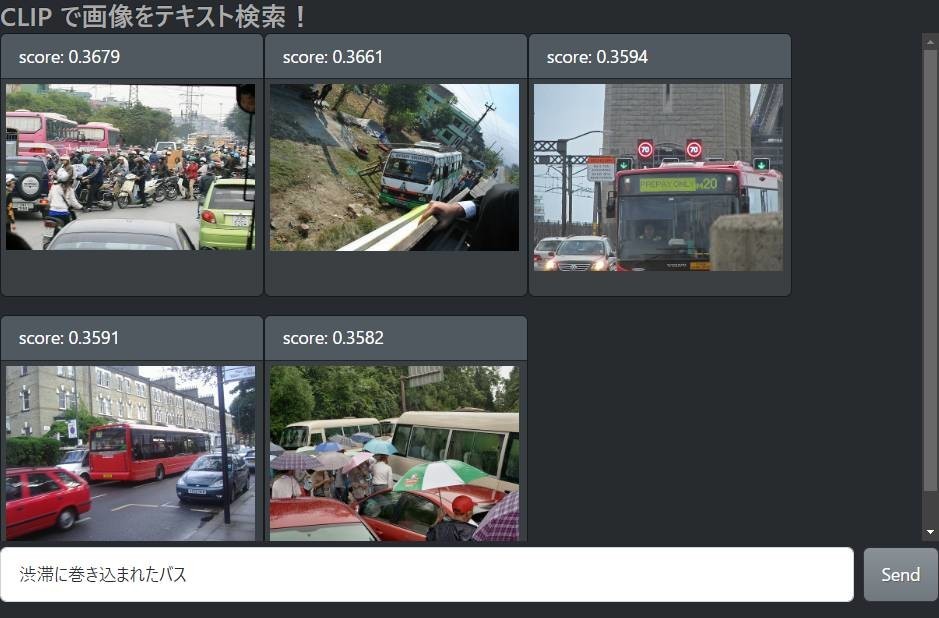
期待以上にいい結果が得られてホクホクしてしまいます。
他の検索結果例については、冒頭の資料 or 録画をごらんください。
この手の深層学習の「いい感じの結果」は厳選前提だったりすることがよくあります。この CLIP 検索は、まあもちろんダメな結果もあるはあるんですが、どちらかというと「おもしろい結果が簡単にたくさん得られてしまって、どれをスライドに採用するか悩む」というくらい、安定して良い検索結果が得られました。
VRC-LT の歓談中に「検索結果のスコアが 0.3 くらいと低い」という良い指摘がありました。これは 512次元のような高次元空間では低次元の常識が成り立たず、ランダムなベクトル同士のコサイン類似度は 0 の周辺に集中する分布を持つ(つまり、ほぼ直交する)という事情があります。つまりコサイン類似度 = 0.3 というのはその分布においては実はかなり高い値で、ベクトル同士もかなりよく似てくるんですね。
さて最後に実装を載せて終わりましょう。普通なら github とかに載せるところでしょうが、コードの短さを見てもらうために記事にそのまま貼り付けることにします。
VRC-LT のプレゼンでは、スライド一枚にプログラムコードを収めて短さを強調していましたが、実際、web サーバ部分込みで 70行程度に収まっています。
画像は COCO と ImageNette というデータセットから適当に借りてきた約5万枚を使っています。
好きな画像を用意して、「# 画像を置いてあるパス」のところを適宜書き換えてください。
バリエーションの幅広い、十分な枚数の画像を用意しないと結果がおもしろくならないので、画像の用意が今回の話で一番難しいところでしょう(笑)。
import os, io, base64, glob, tqdm from PIL import Image import tornado.ioloop, tornado.web import torch import japanese_clip as ja_clip device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = ja_clip.load("rinna/japanese-clip-vit-b-16", cache_dir="/tmp/japanese_clip", device=device) tokenizer = ja_clip.load_tokenizer() DATASETS = [ # 画像を置いてあるパス "/media/hdd/dataset/imagenette2-320/train/**/*.JPEG", "/media/hdd/dataset/imagenette2-320/test/**/*.JPEG", "/media/hdd/dataset/coco/val2017/*.jpg", "/media/hdd/dataset/coco/test2017/*.jpg", ] imglist = [] for path in DATASETS: imglist.extend(glob.glob(path)) if os.path.exists("image_features.pt"): norm = torch.load("image_features.pt") else: features = [] for path in tqdm.tqdm(imglist): img = Image.open(path) image = preprocess(img).unsqueeze(0).to(device) with torch.no_grad(): features.append(model.get_image_features(image)) features = torch.cat(features) norm = features / torch.sqrt((features**2).sum(axis=1)).unsqueeze(1) torch.save(norm, "image_features.pt") def read(path): with open(path, "rb") as f: return base64.b64encode(f.read()).decode("utf-8") def search(query): encodings = ja_clip.tokenize(query, tokenizer=tokenizer) with torch.no_grad(): text_features = model.get_text_features(**encodings) textnorm = text_features / torch.sqrt((text_features**2).sum()) sim = norm.matmul(textnorm.squeeze(0)) topk = torch.topk(sim, 5) return [{"image_base64":read(imglist[topk.indices[i]]), "score":topk.values[i].item()} for i in range(5)] class MainHandler(tornado.web.RequestHandler): def get(self): query = self.get_argument("query", "").strip() if query!="": topk = search(query) else: topk = [] self.render("main.html", query=query, topk=topk) if __name__ == "__main__": dir = os.path.dirname(__file__) app = tornado.web.Application([ ("/", MainHandler), ], template_path=os.path.join(dir, "template"), static_path=os.path.join(dir, "static"), compiled_template_cache=False, ) app.listen(8000) print("Listening...") tornado.ioloop.IOLoop.current().start()
あと2つのファイルを置くだけで動きます。
まず以下のような tornado の HTML テンプレートを template/main.html に置きます。
渡された画像リストを展開するだけの簡単なものです。
次に スタイルシートを static/bootstrap.css に置きます。bootstrap に対応させてますので、好きなスタイルを選んでください。
LT で見せた実装では bootswatch の slate を使いました。
<!DOCTYPE html> <html lang="ja" style="height:100%"> <head> <meta charset="utf-8"> <title>CLIP Search</title> <link href="{{ static_url("bootstrap.css") }}" rel="stylesheet"/> <style> .card { --bs-card-spacer-y: .3rem; --bs-card-spacer-x: .3rem; float: left; width: 240px; height: 240px; } .card-text { max-width: 99%; max-height: 99%; } </style> </head> <body style="height:100%"> <div id="main" style="height:100%; box-sizing:border-box; padding: 30px 0 70px"> <h1 style="position:absolute; top:0">CLIP で画像をテキスト検索!</h1> <div id="chat-log" style="height:100%; overflow-y:auto"> {% for x in topk %} <div id="card-template"> <div class="card text-white bg-primary mb-3"> <div class="card-header">score: {{ f"{x['score']:.04f}" }}</div> <div class="card-body"> <img class="card-text" src="data:image/jpeg;base64,{{ x['image_base64'] }}" /> </div> </div> </div> {% end %} </div> <div id="chat-input" class="form-group" style="position:absolute; bottom:0; width:100%; padding-bottom: 15px"> <form id="prompt_form" class="d-flex" method="get"> <input id="query" name="query" class="form-control me-sm-2" type="text" placeholder="Query" value="{{ query }}"> <button id="send_btn" class="btn btn-secondary my-2 my-sm-0" type="submit">Send</button> </form> </div> </div> </body> </html>