久しぶりの更新。
学生さんが好きなものを開発するのを支援するサイボウズ・ラボユースという制度が始まってもう7年目。
先日、4年ぶりにラボユース合宿が開催された。
詳しくはリンク先の記事を見てもらいたいが、要は、泊まり込みで朝から晩までみっちりコードを書きまくり、夜も思う存分プログラミング談義な合宿に参加できるということ。朝昼晩のごはんもついてる。温泉もある(※開催地による)。もちろん費用はサイボウズ持ち。
サイボウズ・ラボユースは通年募集、まだまだ応募できる。興味あればぜひ。宣伝終わり。
さて、合宿にはサイボウズ・ラボの社員ものこのこついていく。
いろいろ話したり、指導したりもするのだが、やっぱりコードを書いている時間が一番長い。
しかしせっかくの合宿という場なのに、いつもと同じコードを書くのは芸がない。
そこで Memory Networks を実装してみることにした。
実は Memory Networks が、あまり好きではない。むしろ嫌いかもw。
だからこそ、食わず嫌いに陥らないために、いつもと違う雰囲気の中で実装してみようという志なわけだ。
と偉そうに言ってみたが、論文をろくに精読もしていない状態から3日間で実装するのはさすがに無謀で、合宿後も結構みっちりコード書いたり実験したりする羽目に(苦笑)。
Memory Networks とは、記憶した知識から質問にふさわしい情報を取り出し、回答を生成するモデル。
直接的には質問応答問題だが、汎用人工知能に発展させたいという野望が見え隠れしている。
日本語ならこちらのブログ記事か、MLP シリーズの「深層学習による自然言語処理」か。
- 論文解説 Memory Networks (MemNN) - ディープラーニングブログ
- 深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ) | 坪井祐太, 海野裕也, 鈴木潤 | 工学 | Kindleストア | Amazon
前者はかなり詳しいが、さすがにこの記事だけで実装できるわけではなく、元論文を読む必要がある。
代表的な論文はこちらの3本だろう。
- Weston, Jason, Sumit Chopra, and Antoine Bordes. "Memory networks." arXiv preprint arXiv:1410.3916 (2014).
- Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. "End-to-end memory networks." Advances in neural information processing systems. 2015.
- Kumar, Ankit, et al. "Ask me anything: Dynamic memory networks for natural language processing." International Conference on Machine Learning. 2016.
素の Memory Networks は、「記憶にあるどの知識を参照するべきか」という情報が質問に付いているという前提のモデルである。
さすがにそれはちょっとなー、という人には、「どの知識を参照するべきか」も一緒に学習する End-to-End Memory Networks がある。
ネットワークの大きさも手頃で、3日間で実装するにはちょうどいいだろう(できなかったが)。
さらに発展した Dynamic Memory Networks では、「人間の推論はいきなり回答が出てくるのではなく、段階を踏んでいる」ことをモデルに組み込んだ。
End-to-End Memory Networks を実装してみて、その苦手なタスクを目の当たりにすれば、なるほど、そっちへ発展させたくなる気持ちがよくわかる。
End-to-End Memory Networks
ここで End-to-End Memory Networks の詳細に踏み込んだら、いつまでたっても実装の話に入れない。
社内勉強会用に End-to-End Memory Networks の資料を作ったので、モデルの概略は後ほどそちらを公開するときに語ることにする。
ここではモデルは既知として、実装によって確認できた知見をメインにしよう。
End-to-End Memory Networks のモデルそのものはシンプルかつ小さいので、モデルを記述するだけなら、どの深層学習ライブラリでも 10行ちょいで書けるだろう。
ただし、それだけでは全く性能が出ない。そこでさまざまな「工夫」を追加で施すことになる。
- Temporal Encoding
- Random Noise
- Position Encoding
- Linear Start
- 勾配の切り詰め
素朴な End-to-End Memory Networks では、知識は記憶に追加されるだけであり、質問との関連を推定するときに時刻は考慮しない。
しかしそれでは、"Sandra moved to the garden." と "Sandra journeyed to the bathroom." という2つの知識の記憶があるとき、"Where is Sandra?" と質問されても、どっちの知識が今の Sandra の情報を表しているのかわからない。
そこで「記憶の知識の時刻と、質問時の時刻の差」の情報を組み込むのが Temporal Encoding だ。
これを入れないと、笑っちゃうくらい性能が出ない(タスクによってはランダムと同等まで落ちる)ので、Temporal Encoding は必須である。
ただし、Memory Networks の理想の姿であれば、知識が入ってきたときに「Sandra は garden に行った」という記憶を「 garden に行った後、bathroom に行った」に更新(Generalization)するべきなのだろう。
そこをモデル化していないツケを Temporal Encoding というヒューリスティックで払ってるわけだ。
Random Noise は、記憶の系列に 10% の確率で 0 ベクトルを挿入して時刻をずらすことで、Temporal Encoding が特定の訓練データに過適合するのを防ぐ。
論文ではかなり効果があるようだが、手元の実験ではいくつかのタスクで汎化性能がちょっこり上がった? くらいの印象。
素朴な End-to-End Memory Networks では「単語ベクトルの総和」を文のベクトルとするのだが、それだけでは "Mary handed the football to John." と "John passed the football to Mary." がほとんど区別できない。Position Encoding は単語ベクトルを加算するときに、ベクトルの要素ごとに単語の文中の位置に応じた重みを与えることで、単語の位置の情報を文ベクトルに落とし込む。
ここで x_ij は i 番目の文の j 番目の単語(1-hot vector)、A は単語を分散表現ベクトルに変換する行列、J は文長(単語数)、d は分散表現の次元、k=1,…,d は分散表現ベクトルの要素インデックス。
この式は次のように変形することで、固定長の演算に落とし込むことができる。
データに対しては、単語頻度行列を単純和 と重み付き和
の2つをあらかじめ計算しておけばよい。
文を RNN とかでベクトル化すればこんな工夫はしなくていいだろうが、学習がテキメンに重くなる。
この手法ならネットワークの大きさを固定できるので、速度的には大幅に有利だろう。
Linear Start は、質問と各記憶の関連度を確率に落とし込むソフトマックス層がネットワークの中間にあるのだが、これを学習の初期に取り除いてしまうという手法。
学習が早くなり、local minimum に捕まりにくい……と論文は言うのだが、正直効果は実感できなかった。
validation loss が上昇したらソフトマックス層を挿入して本来のモデルに戻すので、Linear Start するしないはせいぜい初期値の影響程度。上述の固定長で実装すればかなり高速に学習できてしまうので、初期値を変えて何回かトライする&ちょっと長めに Epoch 回すくらいで十分 Linear Start を上回れるんじゃないの?
学習については、"No momentum or weight decay was used." と書かれており、生 SGD を使うことが明示されている。
しかし学習率を 1e-5 以下にしても、かなりの頻度であっさり inf に飛ぶ。特に上の Linear Start を組み込んだら、inf に飛ばずに学習できる方がまれになる。そこで、backward 後に、各パラメータごとに勾配のノルムが 40 を超えていたら、スカラー倍して 40 に納める、という強引な変換を入れる。
こんなの初めて見たんだけど、アリなのかな? GAN の学習が不安定なのとか、これでうまくいく割合が増えたり?
ただ、そんな勾配の切り詰めなんかしなくても、Adam でさっくり学習できたりする(苦笑)*1。まあ、Momentum 系特有の乱高下はちょいちょい起きるけど。
あとは学習率を細かく変えるとか、ミニバッチは 32 とか、指定されてるけど、そのへんはネグった。
というわけで実装はこちら。
当初、ベクトルを計算するところで文の長さに応じた処理が必要になると思って Chainer を選んだのだが、固定長で済むので Tensorflow と使うべきだった。スパース行列もサポートしているし。無念。
Chainer から Tensorflow への移植がどんなものかという興味もあるので、気が向いたら Tensorflow で実装し直すかもしれない。たぶん、そんなに大変じゃない。
データセットは bAbI。Facebook が Memory Networks のために作った?
ごくごく単純な文法と、ごくごく小さな語彙セットで構成され、しかも回答は1単語という、名前の通りとても簡単な質問応答データセット。20 のタスクが用意されているが、否定文を含むのはその中の1つだけだったり。
リンク先から bAbI Tasks Data 1-20 (v1.2) をダウンロードして展開(ファイル名は tasks_1-20_v1-2.tar.gz )、e2emn.py を実行すると Task 1 で学習・推論する。
他のタスクに変えたり、上述の工夫を On/Off したり、Adam で学習したりもできるので、ヘルプ見て。
Task 1〜20 それぞれについて、初期値を変えて5回学習、それぞれ一番良いエラー率を拾ったものがこちら。
論文に合わせて、BoW(Temporal Encodingのみ)と、Position Encoding, Linear Start, Random Noise を順に有効にしていったものについて実験している。
大勢には影響ないだろうと思って validation=test にしてる。手抜き。
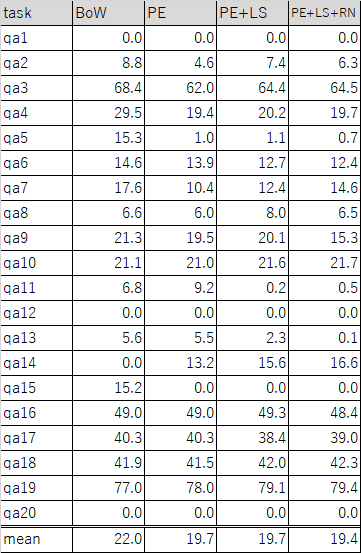
細かいところは色々違ってるが、かなり論文に近い結果が再現できた?
違いを産んでいるのは、やっぱりミニバッチを実装していないことかもしれない。
トライしなかったわけではないのだが、ソフトマックス層の幅がデータごとに違うのをうまく実装するのがめんどくさくなって、半日くらいであきらめてしまった。