えらく間隔があいてしまった。
LDA の結果を評価しつつ、前回やった LDA の Collapsed Variational Bayesian(CVB) 推論にて、初期化に一工夫入れて、少ないイテレーションで定性的によい結果を得られることを確認していたので、その解説も入れていこう。
- Latent Dirichlet Allocations の Python 実装 - 木曜不足
- Latent Dirichlet Allocations(LDA) の実装について - 木曜不足
- LDA で実験 その1:stop words の扱い方でどう変わる? - 木曜不足
- LDA で実験 その2:初期値を逐次サンプリングにしてみた - 木曜不足
- LDA の Collapsed Variational Bayesian 推論 - 木曜不足
CVB0 では γ_ijk の更新式が以下の形で得られる。
この γ_ijk の初期値を何らかの方法で決めてあげる必要がある。
真っ先に思いつくのは、適当なパラメータ(素直に行けばα)を使って、ディリクレ分布からサンプリングしてあげる方法。多分これが「通常のやりかた」……だと思う。
ところが詳しくは後で見るが、この方法では perplexity が下がりきったところで推論を止めても、ストップワードが複数のトピックに散ってしまっていて、明らかに都合の悪い結果になる。
そこで Collapsed Gibbs Sampling(CGS) でやった 初期値を逐次サンプリングしてみた と同様のことを CVB でも考えたい。
そのためには、γ_ijk にどういう分布を想定すればいいか。
γ_ijk は変分ベイズによって導出された z_ijk の期待値(いわゆる「負担率」)であることを考えれば、上の更新式の右辺を初期値を定めながら逐次更新&正規化したものを e_ijk とすると*1、γは次のディリクレ分布からサンプリングすれば良さそうだ。
ただ python / numpy でこれを実装するときに気をつけないといけないのが、 numpy.random.mtrand.dirichlet() に極端なパラメータを与えるとまれに NaN や Inf を返すことがある点。そこで本実装では numpy.isfinite() で第1要素をチェックして、有限値でなければ Dir(α) からサンプリングし直している。
それらを含めた実装が github においてある。
さらに、CGS と CVB0 を、それぞれ初期化の工夫(以下、smart init)を行った場合とそうでない場合を比べるスクリプト lda_test.py も用意した。
- https://github.com/shuyo/iir/blob/master/lda/lda.py
- https://github.com/shuyo/iir/blob/master/lda/lda_cvb0.py
- https://github.com/shuyo/iir/blob/master/lda/vocabulary.py
- https://github.com/shuyo/iir/blob/master/lda/lda_test.py
実行には Python と numpy, NLTK が必要(lda や lda_cvb0 をライブラリとして使うだけなら NLTK は不要)。
次のように実行すると、CVB0(smart init なし)、CVB0(smart init あり)、CGS(smart init なし)、CGS(smart init あり) の順に実行して、各イテレーションごとの perplexity の値、それから perplexity が上昇に転じたときとイテレーションが指定した回数回ったときにトピックごとの単語分布の上位 20件を出力する。
$ python ./lda_test.py -c0:500 --seed=0 --df=1 -k 50 -i 200
lda_test.py のオプションの意味も一応書いておく。他にもあるので -h で見てもらえば。
- -c : コーパスとして使う NLTK のブラウンコーパスの範囲を指定
- --seed : 乱数のシード
- --df : document frequency による足切り(語彙セットをコーパスから取得するが、df が指定回数以下なら語彙セットから除外)
- -k : トピック数
- -i : イテレーションの回数
乱数のシードを指定することで、同じ結果を再現できる。以下の結果に疑問があって検証したいという場合も、上のコマンドで各自の環境でも再現できるはずだ。
というわけで、いよいよ結果を見ていこう。
まずは定量的な評価ということで 200回のイテレーションで perplexity(小さいほどよい) がどのように変化したかを確認する。
4つの手法それぞれについて、perplexity を縦軸にイテレーション回数を横軸にとって描いたチャートがこちら。

perplexity が下がった付近の動きをよく見るために、拡大。
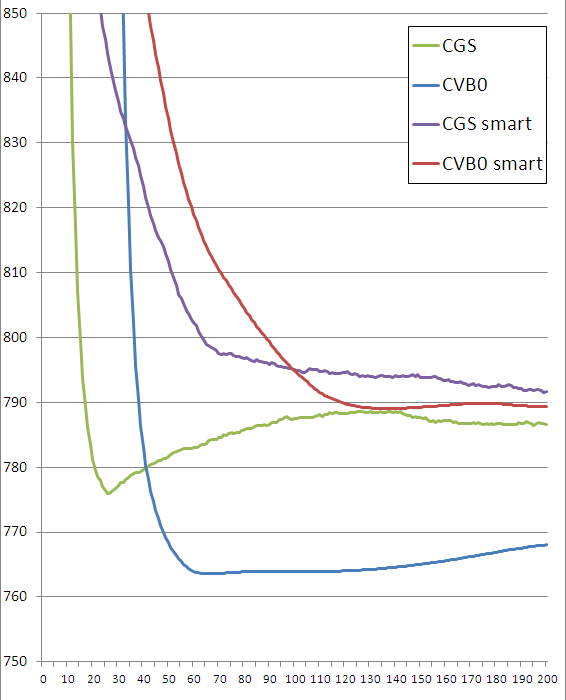
また各手法で perplexity が減少から増加に反転したときのイテレーションの回数とそのときの値も拾った。なお collapsed Gibbs sampling では「2回連続で最小値を更新できなかったとき」を拾っている。
| algorithm | iteration | perplexity |
|---|---|---|
| CGS | 26 | 775.957715 |
| CGS smart | 73 | 797.440801 |
| CVB0 | 67 | 763.610870 |
| CVB0 smart | 138 | 789.008105 |
こうして見ると、perplexity の点では「 smart init 無しの方が圧倒的に収束が速く、perplexity も小さい」ことがわかる。
この傾向は、乱数シードやトピック数などをかえてもおおむね変わらない。
というわけで定量的に評価する限りでは、smart init にいいところは何一つ無い。
が、出力されたトピック語との単語分布を見てみると、印象が一変する。
全体でもっとも perplexity が低いのは CVB0 (smart init なし) の 67回目のイテレーション時であるわけだが、そのときのトピック-単語分布を見ると*2、"parker" という単語がトップ(生起確率最大)になっているトピックが 50 トピック中 30 個もあった。"the" がトップになっているトピックも 8 個あった。
イテレーションを200 回実行した後でも、"parker" はほとんど出てこなくなるが、"nemesis" という単語がトップのトピックが 33個、"the" がトップのトピックがまだ 6個残っていた。
つまり、ほとんどのトピックが重複しているかゴミのどちらか、という状態。
一方、smart init ありの CVB0 で perplexity が最小となるのは 138回目だが、その時点でのトピック=単語分布は、ストップワードのトピック("the" がトップ)が3つ出来てしまっているのを除くと、重複トピック(トップ20の単語がほぼ共通している)は存在していなかった。
CGS の smart init あり/なしも同様な傾向を示した。
ちなみに、smart init なしの CVB0 や CGS でさらに推論を回していくと、重複トピックを徐々に統合しながら perplexity がしばらく増加を続けた後、ある時点でまた減少に転じ、1回目の収束値を超えてさらに perplexity が下がっていく、という挙動を示す。
というわけで、perplexity だけ見てても本当に良くなっているのかどうかわかんないよ! という話。
【追記】
書き忘れ。
グラフだけを見ると CVB0 より CGS の方が良さそうだが、上記設定(500文書、50トピック、200イテレーション)での実行時間は手元の環境で CVB0 が 2500秒、CGS が 9700秒とほぼ4倍の差になる。
これは前回も書いたが、CGS の計算量が文書長に比例するのに対し、 CVB0 のは語彙数に比例すること、そしてサンプリング(乱数生成)という結構重い処理をしなくていいことが効いている。
というわけで収束判定のしやすさまで含め、比較した手法の中では CVB0 (smart init あり) が一番良さそう、というのが現在の結論。
【/追記】