End-to-End Memory Networks の勉強会資料+補足
前記事で End-to-End Memory Networks の実装を公開してたが、さらに社内勉強会の資料も公開する。
モデルもわかるように一応説明したつもり。
以下、前記事で書き忘れたこと+補足。
- 実装は CPU / GPU 両対応している。が、GPU の方が遅い(苦笑)。たぶんデータの渡し方が悪い&モデルが小さいので、演算時間がオーバーヘッドを上回れないのだろう。データの渡し方を工夫すれば改善するだろうが、Random Noise がどうせ台無しにするので、そこを頑張るのはやめた。
- 質問と記憶から応答情報を生成するのが基本。その応答情報を新しい質問とみなしてフィードバックすることで RNN 的な多層ネットワークを構成することができる。表現力が上がる……のかな? 実装では層の数をオプションで指定できるようにしているので、1層と3層で傾向がどのように変わるのか確認してみるのも面白いかもしれない。
- こちらのブログ記事 http://deeplearning.hatenablog.com/entry/memory_networks にて、Memory Network の IGOR フレームワークの名前の由来について「ちなみに I, G, O, R の 名前の由来はフランケンシュタイン博士の助手イゴール (IGOR) である」と記述がある。Memory Networks が汎用 AI を目指している野望がチラ見えるなあと感心していたのだが、結構頑張って探してもソースが見つからない。その代わり、ホームズの助手といえばワトソンであるようにフランケンシュタイン博士の助手といえば IGOR とよく知られている(らしい)が、原作の小説では博士に助手はいない、映画の第1作で初めて助手が登場するが、その時の名前は IGOR ではなかった、という余計な知識が記憶に追加されてしまった。( e.g. https://en.wikipedia.org/wiki/Frankenstein#The_creature )
End-to-End Memory Networks を実装してみた
久しぶりの更新。
学生さんが好きなものを開発するのを支援するサイボウズ・ラボユースという制度が始まってもう7年目。
先日、4年ぶりにラボユース合宿が開催された。
詳しくはリンク先の記事を見てもらいたいが、要は、泊まり込みで朝から晩までみっちりコードを書きまくり、夜も思う存分プログラミング談義な合宿に参加できるということ。朝昼晩のごはんもついてる。温泉もある(※開催地による)。もちろん費用はサイボウズ持ち。
サイボウズ・ラボユースは通年募集、まだまだ応募できる。興味あればぜひ。宣伝終わり。
さて、合宿にはサイボウズ・ラボの社員ものこのこついていく。
いろいろ話したり、指導したりもするのだが、やっぱりコードを書いている時間が一番長い。
しかしせっかくの合宿という場なのに、いつもと同じコードを書くのは芸がない。
そこで Memory Networks を実装してみることにした。
実は Memory Networks が、あまり好きではない。むしろ嫌いかもw。
だからこそ、食わず嫌いに陥らないために、いつもと違う雰囲気の中で実装してみようという志なわけだ。
と偉そうに言ってみたが、論文をろくに精読もしていない状態から3日間で実装するのはさすがに無謀で、合宿後も結構みっちりコード書いたり実験したりする羽目に(苦笑)。
Memory Networks とは、記憶した知識から質問にふさわしい情報を取り出し、回答を生成するモデル。
直接的には質問応答問題だが、汎用人工知能に発展させたいという野望が見え隠れしている。
日本語ならこちらのブログ記事か、MLP シリーズの「深層学習による自然言語処理」か。
- 論文解説 Memory Networks (MemNN) - ディープラーニングブログ
- 深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ) | 坪井祐太, 海野裕也, 鈴木潤 | 工学 | Kindleストア | Amazon
前者はかなり詳しいが、さすがにこの記事だけで実装できるわけではなく、元論文を読む必要がある。
代表的な論文はこちらの3本だろう。
- Weston, Jason, Sumit Chopra, and Antoine Bordes. "Memory networks." arXiv preprint arXiv:1410.3916 (2014).
- Sukhbaatar, Sainbayar, Jason Weston, and Rob Fergus. "End-to-end memory networks." Advances in neural information processing systems. 2015.
- Kumar, Ankit, et al. "Ask me anything: Dynamic memory networks for natural language processing." International Conference on Machine Learning. 2016.
素の Memory Networks は、「記憶にあるどの知識を参照するべきか」という情報が質問に付いているという前提のモデルである。
さすがにそれはちょっとなー、という人には、「どの知識を参照するべきか」も一緒に学習する End-to-End Memory Networks がある。
ネットワークの大きさも手頃で、3日間で実装するにはちょうどいいだろう(できなかったが)。
さらに発展した Dynamic Memory Networks では、「人間の推論はいきなり回答が出てくるのではなく、段階を踏んでいる」ことをモデルに組み込んだ。
End-to-End Memory Networks を実装してみて、その苦手なタスクを目の当たりにすれば、なるほど、そっちへ発展させたくなる気持ちがよくわかる。
End-to-End Memory Networks
ここで End-to-End Memory Networks の詳細に踏み込んだら、いつまでたっても実装の話に入れない。
社内勉強会用に End-to-End Memory Networks の資料を作ったので、モデルの概略は後ほどそちらを公開するときに語ることにする。
ここではモデルは既知として、実装によって確認できた知見をメインにしよう。
End-to-End Memory Networks のモデルそのものはシンプルかつ小さいので、モデルを記述するだけなら、どの深層学習ライブラリでも 10行ちょいで書けるだろう。
ただし、それだけでは全く性能が出ない。そこでさまざまな「工夫」を追加で施すことになる。
- Temporal Encoding
- Random Noise
- Position Encoding
- Linear Start
- 勾配の切り詰め
素朴な End-to-End Memory Networks では、知識は記憶に追加されるだけであり、質問との関連を推定するときに時刻は考慮しない。
しかしそれでは、"Sandra moved to the garden." と "Sandra journeyed to the bathroom." という2つの知識の記憶があるとき、"Where is Sandra?" と質問されても、どっちの知識が今の Sandra の情報を表しているのかわからない。
そこで「記憶の知識の時刻と、質問時の時刻の差」の情報を組み込むのが Temporal Encoding だ。
これを入れないと、笑っちゃうくらい性能が出ない(タスクによってはランダムと同等まで落ちる)ので、Temporal Encoding は必須である。
ただし、Memory Networks の理想の姿であれば、知識が入ってきたときに「Sandra は garden に行った」という記憶を「 garden に行った後、bathroom に行った」に更新(Generalization)するべきなのだろう。
そこをモデル化していないツケを Temporal Encoding というヒューリスティックで払ってるわけだ。
Random Noise は、記憶の系列に 10% の確率で 0 ベクトルを挿入して時刻をずらすことで、Temporal Encoding が特定の訓練データに過適合するのを防ぐ。
論文ではかなり効果があるようだが、手元の実験ではいくつかのタスクで汎化性能がちょっこり上がった? くらいの印象。
素朴な End-to-End Memory Networks では「単語ベクトルの総和」を文のベクトルとするのだが、それだけでは "Mary handed the football to John." と "John passed the football to Mary." がほとんど区別できない。Position Encoding は単語ベクトルを加算するときに、ベクトルの要素ごとに単語の文中の位置に応じた重みを与えることで、単語の位置の情報を文ベクトルに落とし込む。
ここで x_ij は i 番目の文の j 番目の単語(1-hot vector)、A は単語を分散表現ベクトルに変換する行列、J は文長(単語数)、d は分散表現の次元、k=1,…,d は分散表現ベクトルの要素インデックス。
この式は次のように変形することで、固定長の演算に落とし込むことができる。
データに対しては、単語頻度行列を単純和 と重み付き和
の2つをあらかじめ計算しておけばよい。
文を RNN とかでベクトル化すればこんな工夫はしなくていいだろうが、学習がテキメンに重くなる。
この手法ならネットワークの大きさを固定できるので、速度的には大幅に有利だろう。
Linear Start は、質問と各記憶の関連度を確率に落とし込むソフトマックス層がネットワークの中間にあるのだが、これを学習の初期に取り除いてしまうという手法。
学習が早くなり、local minimum に捕まりにくい……と論文は言うのだが、正直効果は実感できなかった。
validation loss が上昇したらソフトマックス層を挿入して本来のモデルに戻すので、Linear Start するしないはせいぜい初期値の影響程度。上述の固定長で実装すればかなり高速に学習できてしまうので、初期値を変えて何回かトライする&ちょっと長めに Epoch 回すくらいで十分 Linear Start を上回れるんじゃないの?
学習については、"No momentum or weight decay was used." と書かれており、生 SGD を使うことが明示されている。
しかし学習率を 1e-5 以下にしても、かなりの頻度であっさり inf に飛ぶ。特に上の Linear Start を組み込んだら、inf に飛ばずに学習できる方がまれになる。そこで、backward 後に、各パラメータごとに勾配のノルムが 40 を超えていたら、スカラー倍して 40 に納める、という強引な変換を入れる。
こんなの初めて見たんだけど、アリなのかな? GAN の学習が不安定なのとか、これでうまくいく割合が増えたり?
ただ、そんな勾配の切り詰めなんかしなくても、Adam でさっくり学習できたりする(苦笑)*1。まあ、Momentum 系特有の乱高下はちょいちょい起きるけど。
あとは学習率を細かく変えるとか、ミニバッチは 32 とか、指定されてるけど、そのへんはネグった。
というわけで実装はこちら。
当初、ベクトルを計算するところで文の長さに応じた処理が必要になると思って Chainer を選んだのだが、固定長で済むので Tensorflow と使うべきだった。スパース行列もサポートしているし。無念。
Chainer から Tensorflow への移植がどんなものかという興味もあるので、気が向いたら Tensorflow で実装し直すかもしれない。たぶん、そんなに大変じゃない。
データセットは bAbI。Facebook が Memory Networks のために作った?
ごくごく単純な文法と、ごくごく小さな語彙セットで構成され、しかも回答は1単語という、名前の通りとても簡単な質問応答データセット。20 のタスクが用意されているが、否定文を含むのはその中の1つだけだったり。
リンク先から bAbI Tasks Data 1-20 (v1.2) をダウンロードして展開(ファイル名は tasks_1-20_v1-2.tar.gz )、e2emn.py を実行すると Task 1 で学習・推論する。
他のタスクに変えたり、上述の工夫を On/Off したり、Adam で学習したりもできるので、ヘルプ見て。
Task 1〜20 それぞれについて、初期値を変えて5回学習、それぞれ一番良いエラー率を拾ったものがこちら。
論文に合わせて、BoW(Temporal Encodingのみ)と、Position Encoding, Linear Start, Random Noise を順に有効にしていったものについて実験している。
大勢には影響ないだろうと思って validation=test にしてる。手抜き。
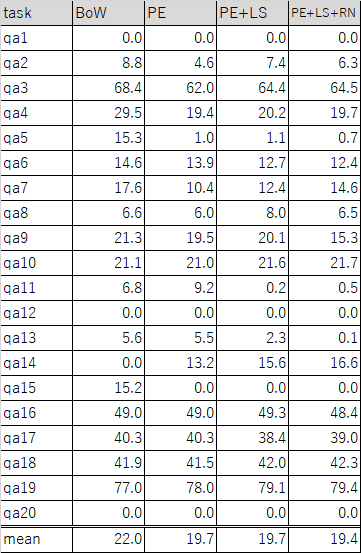
細かいところは色々違ってるが、かなり論文に近い結果が再現できた?
違いを産んでいるのは、やっぱりミニバッチを実装していないことかもしれない。
トライしなかったわけではないのだが、ソフトマックス層の幅がデータごとに違うのをうまく実装するのがめんどくさくなって、半日くらいであきらめてしまった。
コサイン類似度が高いベクトルはどれくらい似ているか(岩波データサイエンス刊行イベントより)
岩波データサイエンス vol.2 の発刊を記念して、刊行トークイベント「統計的自然言語処理 - ことばを扱う機械」が 3月3日 に開催されました。
- 岩波データサイエンス Vol.2 : 岩波データサイエンス刊行委員会 : 本 : Amazon.co.jp
- トークイベント「統計的自然言語処理ーことばを扱う機械」(岩波データサイエンス Vol.2 刊行記念) - connpass
イベントの様子はニコニコ動画さんで生中継されましたが、その録画は YouTube で公開させてもらっています。
【トークイベント「統計的自然言語処理ーことばを扱う機械」(岩波データサイエンス Vol.2 刊行記念) - YouTube】
自然言語処理に詳しい人でも詳しくない人でもおもしろい本&イベントになったので、ぜひ一度手にとって見てもらえると嬉しいです。
よくわからないけどちょっと味見してみようかなという人には、賀沢さんの招待講演がユーモアたっぷりですので、まずはそれを笑って楽しんでみては。
以上、1ヶ月遅れ(刊行からは2ヶ月遅れ……)の宣伝終わり。
さて、上記イベントで東北大の岡崎先生が、ご発表の冒頭で word2vec で "Tokyo" と "Osaka" のベクトルが似てるという話をしてくださった。
word2vec によって学習した300次元のベクトルそれぞれをplotして、
「結構似てませんか」
「びっくりしたんですけど、視覚で見ても結構似てるなとわかる」
「このくらいの(コサイン)類似度(0.84)だと視覚的に見てもわかるんだな」
 (岡崎先生の発表動画より)
(岡崎先生の発表動画より)
とやらかす(失礼)と、会場はドッと受けていたわけだが、実際見た目よく似てる(よね?)。
まあ「見た感じ似てる」とかいうのは主観的過ぎるし、人間の習性的にどうしても「違い」に目が行ってしまうかもしれないが、ピークの位置と大きさはほぼ重なっており、少なくともコサイン類似度が高いことには納得できるのではないだろうか。
そう言われてみて遅まきながら気づいたのだが、高次元でコサイン類似度が大きいというのは、実は「めちゃめちゃ似ている」んじゃあないだろうか。
言語処理っぽいことをしてれば、コサイン類似度をクラスタリングとか判別とかに使うわけで、そのとき 0.6 くらいの値しか出ないと、なんか小さいなあとか思っちゃってたけど、 0.6 くらいでも実は「結構かなり似ている」んじゃあないだろうか。
ランダムな2つのベクトルのコサイン類似度はどういう分布になるのだろう。
まず2次元空間で考える。
2次元球の周囲(つまり円)の上で、とりあえず適当なしきい値としてコサイン類似度が 1/2 以上になるのは、それはあるベクトルの±60度の中にもう1つのベクトルが入る場合である。
よって、コサイン類似度>1/2 となる確率は 1/3 だ。
3次元空間だと、3次元球の表面上を考えて、(cosθ>=1/2な面積) / (球の面積) でその確率は 1/4、と少し減る。
4次元以上の一般の n 次元空間でその確率を求めるには一般の n 次元球の表面積(の一部)を計算する必要がある。
ちょっと考えてみたが、めんどくさい方法しか思いつかなかったので、サンプリングで解かせることにした。
1000000 サンプルのうちコサイン類似度が 1/2 を超える割合を求めると、
- 10 次元 では 0.06 (約 1/17)、
- 20 次元 では 0.01 (約 1/100)、
- 30 次元 では 0.0021 (約 1/480)、
- 40 次元 では 0.00042 (約 1/2400)
と、どんどん少なくなっていき、100 次元 では、1000000個サンプリングした中にコサイン類似度が 1/2 以上になる点はなかった。
こうしてみると、300次元でコサイン類似度が 0.84 とか、もしそれがランダムに取ったベクトルだったなら、宝くじに当たるとか言うレベルの話ではないくらい珍しい現象であることがわかる。
コサイン類似度の分布も見てみよう。
上から 2次元、3次元、4次元、10次元、20次元、30次元、40次元、100次元だ。


2次元ではむしろ ±1 の周辺に多く分布しているのが、高次元になればなるほど、ランダムな2つのベクトルのコサイン類似度は 0 の近辺に大きく偏って集中していくことがよくわかる。
300次元の世界では、適当に取った2つのベクトルはほぼ直交している!
人間は2次元3次元までしか直接的には知覚できないので、どうしても2次元3次元あたりの感覚をそのまま高次元にも当てはめてしまいがちだが(次元の呪いの正体)、この分布を見るとコサイン類似度についてもその感覚が非常に危険であることがよく分かる。
今度からコサイン類似度で 0.6 とかいう値になっても「0.6 しかない」ではなく「0.6 もある!」と思うようにしよう。

- 作者: 岩波データサイエンス刊行委員会
- 出版社/メーカー: 岩波書店
- 発売日: 2016/02/17
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (3件) を見る
「続・わかりやすいパターン認識」13章「共クラスタリング」の無限関係モデル(IRM)の数式について #ぞくパタ
続わかりやすいパターン認識、 6章から読み始めたんだけど(ぉぃ)、いきなり式 (6.9) が間違ってた。簡単なミスなので既知だと思うんだけど、正誤表ってどこかにないのかなあ。#ぞくパタ
— Nakatani Shuyo (@shuyo) March 10, 2015
ということを1年近く前につぶやいたりしてたのだが、オーム社のサイトで「続・わかりやすいパターン認識」(以降「ぞくパタ」)の正誤表がちゃんと公開されていることに最近ようやく気づいた。
上のツイートで言っている式 (6.9) ももちろん修正されているし、以下の記事で書いていた8章の問題点もことごとく手当されている。すばらしす。
まあこのツイートやらブログやらを参考にしてもらえたかどうかは定かではないわけだが、どこかで間違いを指摘しておくと反映される可能性がある、というのは勇気づけられる話。
話は変わって、2014/12 から開催されていた「続・わかりやすいパターン認識」読書会が先月めでたく最終回を迎えた、っぽい。
「ぽい」というのは、最後の2回に参加できなかったから。
まあもともと興味のある回にとびとびにしか参加してなかったわけだが、12章後半はある意味ディリクレ過程混合モデルの実装編で、この本のクライマックスだったから是非参加したかった。13章の無限関係モデル(IRM)も一応参加してみたかったところ。
というわけで参加できなかったフォローというか腹いせというか、で無限関係モデルを実装でもしてやろうと思って本を読み始めたのだが……。
まだ読んでいる人が少ないせいだろうか、少なくない数式が結構大胆に間違っている。
まあ、だいたいどの間違いも一目見て間違っていることはわかる(左辺に j がないのに、右辺に消えない j が残っている、とか)ので、抜き打ちの演習みたいなものか。
「これくらい計算できるよね?」という読者への親心を無下にするのも心苦しいが、見つけてしまった間違いはじゃんじゃん指摘してしまおう。
というわけで、この記事はぞくパタ13章の数式の誤りを淡々と指摘するだけの記事であり、IRM(Infinite Relational Model) がなにかわかるような記事ではないので、あらかじめ。
まずは p284 の式 (13.8)。右辺の分母に n が現れているが、実は n なんてどこにも定義されていない。
とか
とか、そういうややこしいのはいろいろ定義されている*1からだまされるかもしれないが、ワナである。
この n の位置に入るのは、 の個数なので正しくは K である。
次は同じ p284 (13.9) 式の新規クラスタのときの式。 という記号が出てくる。
11章12章でさんざん見てきたので、ついうっかり知ってる記号だと思ってしまったかもしれないが、これも未定義である。
G_0 は11章12章ではディリクレ過程の基底分布として使われていた記号だが、13章では2次元の構造を持つクラスタを素のディリクレ過程ではモデリングできず、CRP(中華料理店過程)でモデリングされているため、そもそもディリクレ過程自体が出てこない。
「ディリクレ過程だったら基底分布にあたるもの」なら p281-282 にて導入されているベータ分布が相当する。
では G_0 はベータ分布なのだろうと解釈すると (13.9) 式で困ったことになる。
G_0 はパラメータθ(スカラー)の分布であり、それを束ねた (ベクトル)の分布ではないので、
という書き方は厳密には間違いとなる。
と、なんかややこしげに書いてしまったが、解決方法は簡単。G_0 じゃなくて単に と書いて同時分布にしてしまえばいい。厳密に考えても何の問題もなく、当たり障りもない。いや、この本の表記だと小文字 p か。
次、p287 (13.26) 式。左辺に j がないのに、右辺に消えない j が残る。
これは \prod 忘れなので、単純に正解を記そう。(13.9) 式と同じく未定義 n も手当すると、場合分けの式それぞれ次のようになる。
(13.27) 式も同様なので、略。ただし、n は L になる。
もっとも、K-1+α も L-1+α も k や l に依存せず、どうせ全部足して1にするときに消えてしまうから、どちらにせよ実装では省略してしまってよかったりする(笑)。
最後、p288 (13.28)式。 k,l が消えずに残る。これも \prod 忘れ。
例によって未定義 G_0 があるので、これも と直してあげつつ、2行目の式だけ正しく書きなおすとこうなる。
見つけた間違いはこれで打ち止めだが、2点蛇足。
その1。
この本の積分はちゃんと閉じた形式に計算しつくされており、実装者は自分で計算する必要がほとんどなくてすばらしいのだが、本文最後の積分であるこの だけは計算されていない。
ここまでの計算が全部できていたらこれくらい朝飯前(誇張抜き)なので、例によって抜き打ち演習として残しておいてもいいんだけど、せっかく全部の積分がやっつけられているのに雑魚一匹だけ残しておくのもなんだよなあ。というわけで、計算してしまおう。
その2。
p288 に「P(s^1), P(s^2) は式 (11.11) のイーウェンスの抽出公式で求める」とある。そういえば 12章でもほぼ同じ文言を見た(p265)。
というわけで式 (11.11)「だけ」で P(s) 類が計算できる……と思ったらこれがワナだったりする。
式(11.11)をよく見てみよう。
左辺は P(s) ではなく なのである。実は、P(s) は並べ替えの自由度の分、確率はこれより下がる。
心配しなくても大丈夫、P(s) と の変換式は式 (11.17) としてちゃんと載っている。
というわけで「P(s^1), P(s^2) は式 (11.11) のイーウェンスの抽出公式と式 (11.17) で求める」だと親切である。
と、あれこれ書いたが、当然、ここに書いてあることにも誤りが含まれている可能性はある。もし間違いなどあればご指摘歓迎。
IRM 実装編はまた今度。
【追記】
社内勉強会の資料公開した。
- 無限関係モデル (続・わかりやすいパターン認識 13章)
- https://www.slideshare.net/shuyo/infinite-relational-model
【/追記】
*1: と
では数えている対象が異なるので、個人的にはどちらかは m とか記号を変えて欲しかった。
EMNLP 2015 読み会 #emnlpyomi
10/24 に開催された EMNLP 2015 読み会にのこのこ行ってきた。
主宰の @unnonouno さん、参加者&発表者の皆さん、会場提供してくださったリクルートテクノロジーズさん、おつかれさまでした&ありがとうございました。
Proceedings を見たら、まあ見事に word embeddings だらけ! ちゅうことは読み会は word embeddings 祭りやな! と思ってたら、みんなもそう読んで避けたのか、Proceedings の印象よりだいぶ word embeddings 率が低かった(定量的に確認はしてない)。
ただ、メインはまったく別のモデルでも、特徴量として word embeddings(というか word2vec)を組み込むというのはなんかデフォルトみたいになってきてる気がする。自分が読んだ Topic Model のやつもそうだったし。
休憩時間にもそこらへん話題になり、「使ってなかったら、なんで使ってないのか質疑で突っ込まれるから、使わないわけにいかない説」が出て、うなずけてしまうくらい。
tf-idf みたいな、定番の特徴量として定着するんだろうかなあ。
以下、発表の短い感想(あくまで感想)。読み会資料が公開されているものはそれも。
It’s All Fun and Games until Someone Annotates: Video Games with a Purpose for Linguistic Annotation (@tootles564 さん)
ゲーミフィケーションでアノテーションする話。
スマホになって、かえってレトロやチープなゲームが受けてたりもするから、ありっちゃありと思うけど。
無理にゲーミフィケーションするから、アノテーションをゲームの文脈に組み込まないといけなくなって、結局ゲームもアノテーションも両方破綻しているような気がしないでもない。
reCAPTCHA のように「アノテーションの報酬としてゲームができる」(広告代わり)とか、スプラトゥーンのマッチング待ちの間に遊ぶミニゲーム(イカジャンプ)のように、ちょっとした合間に出てくるので暇つぶし感覚でついついアノテーションしてしまう、っていうのでいいんじゃあないかなあ。ゲームの文脈からも切り離せるし。
Learning Better Embeddings for Rare Words Using Distributional Representations (@Quasi_quant2010 さん)
Skip-Gram が流行ってるけど、レアワードの特徴を捉えるには CBOW の方がよくて、うまく混ぜるとよりいい感じになる話。
質疑でも懸念されてた「コーパスサイズによって閾値を変える必要があるんでないの?」あたりはあるとしても、理屈は納得感高い。
A Graph-based Readability Assessment Method using Word Coupling (@niam さん)
ラベル伝搬で文の難易度を当てるタスクを解く話。
Readablity は、ずいぶんまえだけど少し興味あって調べてたりしてた(といっても機械学習的な手法ではなく、この論文の baseline にも登場している Flesch-Kincaid などのルールなアプローチくらいまでしか手出してないけど)。
途中の行列積のところ、もうちょっと書き下せば意味がわかるようにできる気がしないでもないんだけどなあ。
Long Short-Term Memory Neural Networks for Chinese Word Segmentation (@MasakiRikitoku さん)
中国語の分かち書きがすげー難しそうな例文を正しく分かち書きするには、その文自身をトレーニングデータに含めるしか無さそうな気もするんだがどうだろう。
LSTM(RNN)と系列ラベリングを組み合わせる枠組みは、他の問題にも普通に適用できそうな雰囲気があるけど、すでにポピュラーなアプローチだったりするのかな。
Compact, Efficient and Unlimited Capacity: Language Modeling with Compressed Suffix Trees (@jnishi さん)
Emnlp読み会資料 from Jiro Nishitoba
Compressed Suffix Tree を使って、∞グラムを高速かつ省スペースで構築する話。
道具立ては非常にシンプルなので、なんか初出なの? 感が。
Kneser-Ney でいくら頑張って interpolate しても、一般的なコーパスサイズでは 6 or 7-gram あたりで perplexity は頭打ち、という実感が裏付けられてよかった(小並感)。
Evaluation methods for unsupervised word embeddings (@nozawa0301 さん)
word embeddings いっぱいあるんで比べてみました話。
順位相関で評価したのと Amazon MTurk で評価したのが一致するってのはちょっと嬉しいかも。
最後の方の議論のところは、なにかおもしろそうなことを言っている予感はあるのだけど、ピンとこなかった。元論文読むか。
Effective Approaches to Attention-based Neural Machine Translation (@tkng さん)
エンコーダー/デコーダーモデル+Attention に、さらに local attention なるものを組み込む話。
パッと見、劇的な効果がある雰囲気はない。
エンコーダー/デコーダーモデルで固有名詞が入れ替わってしまうのを抑えられるので十分嬉しいということなのかな。
Humor Recognition and Humor Anchor Extraction (@yag_ays さん)
ユーモア文かそうでないか判定する話。
韻とかいろいろな特徴量を設計して頑張って分類器作るんだけど、baseline の word2vec がそこそこいい性能さくっと叩き出していて、そら word embeddings 流行るわー、という気分に。
そういえば、なぞかけ生成やってはる人いたなあ。
Efficient Methods for Incorporating Knowledge into Topic Models ( @shuyo )
[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowledge into Topic Models from Shuyo Nakatani
大規模トピックでも効率よく学習するのが歌い文句の SparseLDA (Yao+ 2009, モデルとしては生 LDA と等価)に、事前知識を組み込む話。
いつも読み会に参加するときは、10本くらいの論文の中からある程度読み込んでから選ぶのだけど、今回は余裕なくてイントロとモデルを斜め読みしたくらいで選んだら、
- アカデミックの論文はたかだか 1000トピックだが、最近の実用アプリケーションは 100万トピック! とイントロでぶちあげながら、提案手法は事前知識組み込みで遅くなっちゃって、500トピックで評価
- 評価指標に使った Coherence は、事前知識を制約に入れた Dirichlet Forest-LDA などより生 LDA の方が良い数値。その状態で「 提案手法は LDA を上回っている(ただし僅差)」って言われても、その指標を評価に使うのが間違っているとしか思えない
というわけで、選ぶならせめて評価は読まないと、という教訓。
これがもし読み会トリだったら、ものすごいビミョウな空気で終わることになってしまってたので、そうじゃなくて本当に良かった。
A Neural Attention Model for Abstractive Sentence Summarization (@kiyukuta さん)
Attention で文要約する話。
Attention ってソフトなアライメントだよね、って言われて聞くと、なるほどいろんな応用先がありそうだなあという気にさせられる。
「調査観察データの統計科学」読書会資料を公開しました(数式周りをフォロー)
因果推論、特に傾向スコアについて日本語で学ぼうとしたら、第一に名前が挙がるのは「調査観察データの統計科学」だろう。
")
調査観察データの統計科学―因果推論・選択バイアス・データ融合 (シリーズ確率と情報の科学)
- 作者: 星野崇宏
- 出版社/メーカー: 岩波書店
- 発売日: 2009/07/29
- メディア: 単行本
- 購入: 29人 クリック: 285回
- この商品を含むブログ (26件) を見る
ところがこの本、数式を中心に難が多く、読み始めたはいいけど困っているという人がかなり多そうだ。実は社内の機械学習勉強会でこの本を紹介したのだが、数式のフォローがかなり大変で、そこそこ端折ったにもかかわらず、3章が終わるまでに7回ほどかかってしまった。
特に3章頭の「難所」については、社内勉強会の時の資料をもとにメモを書いてブログに公開したりもしている。
ひと段落したら勉強会の資料も公開しようかと思っていたのだが、3章をとりあえず終わらせたところで力尽きて、ほったらかしにしてしまっていた(忘れていたともいう……)。が、上の記事のコメントで公開要請をいただいたので、ようやく重い腰を上げて資料を整え公開した。
1・2章についてはおそらく大きな問題はない。せいぜい、層別解析の紹介がおざなりすぎることくらいだろう(それは他の本で得るべき知識というスタンスなのだと思う)。
3章は、つじつまの合わない数式や記述が正直かなり多い。スライドではできる範囲でフォローしたつもりだがもちろん完全ではない。因果推論が専門なわけでもなんでもないので、「こうならつじつまがあう」という想像に基づくフォロー自体が適切ではない部分だってきっとあるだろう。資料の間違いや勇み足については指摘大歓迎なので、ぜひ。
書籍と対照させながら読んでもらうためのものなので、原則として記号は書籍のものを踏襲している。が、ひとつだけ記号の付け替えを行っている(θの真値をθ_0 から θ^* に)。
理由はスライドの中でも説明しているし、実際に数式を追ってもらったら納得いくと思うが、念のため。
企業で取り扱うデータの多くは、この本で言う「調査観察データ」、つまり実験室的セッティングが許されない状況で集められたデータであり、そんな「調査観察データ」でもバイアスを抑えた分析ができる(かもしれない)傾向スコアは多くの人が興味を持つ可能性があるだろう。
それなのに、数式が追えないという理由だけで詰まったり読まれなかったりするのはもったいない。この資料が「調査観察データの統計科学」を読む人の助けになれば幸いである。
え? 4章以降はって? まだ読んでないっす……。た、たぶん4章以降は3章ほど大変じゃないと思うよ。きっと……。
「続・わかりやすいパターン認識」11章「ノンパラメトリックベイズ」の「クラスタリングの事前確率」について
昨日の「続・わかりやすいパターン認識」読書会にて、「ホップの壺や中華料理店過程のシミュレーションをみると、これを使うと均等にクラスタリングされるのではなく、クラスタサイズが大きいものから順に小さくなっていくようなクラスタリングがされるように見えるのだが、その認識で正しいのか」といった感じの質疑があった。
いい質問。
実は「続・わかりやすいパターン認識」(以降「ぞくパタ」)では、 p225 の「クラスタリングの事前確率の考え方」のところに、ダイレクトにではないがその質問の答えにつながることが書いてあったりする。coffee break というコラムの形になっているので、つい読み飛ばしちゃった人も多いかもしれないが、結構大事なことが書いてあるので一度じっくり読んでみるといい。
そのあたりも含めて読書会でフォローした内容をここにメモしておく。
まずそもそもの話として。
ベイズにおいて、事前確率(事前分布)の選び方に論理的な裏付けがありうるのか、というと、実のところ全く何もない。ぶっちゃけ事前分布はなんでもいい。
手前味噌だが、そのあたりのことは gihyo.jp での機械学習連載で書いたので、興味があれば一度。
理論的にはなんでもいいが、そこに人間様の都合が絡むと、こういう事前分布は困る、とか、こういうのは嬉しい、とか出てくる。
望ましい事前分布の条件として、どんな問題でも共通して求められるとすればこの 2つだろう。
- ありうる事象(今回の場合は分割方法)の確率が非ゼロ
- なんらかの方法で事後分布が計算できる
共役事前分布は後者の「計算できる」を最優先にした選び方になる。共役でなくても、今回のディリクレ過程のように「ギブスサンプリングできる」でもいい。そこらへんの詳細は 12章でやる話なので、ここではとりあげない。
ベイズ公式を見ればわかるが、事前確率がゼロである事象は、たとえどんなデータをもってきても、事後確率もゼロである。よって「ありうる事象」、つまり「答えとして考えられるすべての可能性」には非ゼロの確率を与えておかないといけない。
今やりたいことは「クラスタ数をあらかじめ決めない」なので、クラスタ数が3個でも4個でも5個でも、何個であってもちゃんと非ゼロの確率を持つ事前分布が必要なわけである。
さて、これで冒頭の質問に答える準備ができた。
ここで大事なことは、事前確率は非ゼロでさえあればどんなに小さくても(理論的には)いいということ。
ホップの壺(中華料理店過程)は、色(テーブル)ごとの玉(客)数の偏りが大きい分布だが、均等な分割、たとえば 500個の玉について 100, 100, 100, 100, 100 という割り方にもちゃんと非ゼロの確率が割り振られる。現実には到底観測されることなんかあり得ないほど低い確率だろうけど、ゼロでさえなければ、データが何とかしてくれる期待が持てるわけだ。
ただし、いくら何でもいいといっても、事前分布が「変」であるほど、「正しい答え」にたどり着くには膨大なデータ数が必要になる。逆に言えば、データ数が少ないと事前分布に引きずられる。
例えば 3 クラス× 50 データの iris データセットを 12章のディリクレ過程混合モデルに食わせると、100, 50 の2個のクラスタにまでは分かれるのだが、そこから分割が進まなかったりする*1。k-means (もちろん3クラス決め打ち)などなら、50, 50, 50 に近いところまで行くのだが。
これはおそらく事前分布であるディリクレ過程に引きずられているのだろう。
というわけで冒頭の疑問の答えは、均等な分割もちゃんと行われうるから大丈夫! という点では No だが、事前分布に負けて、希望よりも偏ったクラスタになることもあるという点では Yes でもある。
それなら、中華料理店過程のような偏った分割モデルではなく、もっと一様な分割を考えたらいいのでは? という発想が当然出てくるだろうが、実は可算無限な台を持つ一様分布は作れない(ちょっと考えれば雰囲気はわかる、はず)のと同じ理由で、どうしたって傾斜を持たせるしかなかったりする。
つまり、ディリクレ過程(やホップの壺や中華料理店過程)は、上の「任意クラスタ数で非ゼロ&計算できる」という条件を満たす中で一番易しいものなのだ。
とはいえ、他にもノンパラメトリックベイズのための無限分割モデルは解きたい問題にあわせて考えられており、ぞくパタ 11.4 でちらっと紹介されているピットマン・ヨー過程*2はその代表的な一つである。
読書会では、ピットマン・ヨー過程がなぜかついでに紹介されているっぽい刺身のツマのような扱いを受けていて、あわてて言語処理ではめっちゃ重要ですから! と突っ込んだり(笑)。
ある分野でどんなに有名であっても、その隣接分野ですら知られているとは限らないというよくある現象なんだけどね。